The series so far has described an execution layer — what it must guarantee, where it lives, and why it matters. The practical question for application teams is simpler: how do you actually use it?
The answer starts with who owns the change.
The change belongs to the application team
When a domain model evolves, the consequences rarely stay within a single service.
Adding a new field to an order in a payments domain affects the database schema, the REST API, the Kafka event schema, and often the API gateway. The application team understands these dependencies — and the order in which they must be introduced.
Yet in practice, these changes are executed separately: a Flyway migration for the database, a schema registry push for Kafka, a manual gateway configuration update, and a service deploy. Each step runs independently through a different tool, owned by a different process, sometimes triggered by a different team.
If the order goes wrong, the system breaks in subtle ways. An API exposes a field the database doesn't support. A consumer receives an event it can't parse. Everything looks correct in isolation, but the sequence was never governed — the same class of failure described in Post 5.
The execution layer gives application teams a way to own that sequence — not as a runbook, but as a declared, ordered set of changes that executes with guarantees.
What a change sequence actually looks like
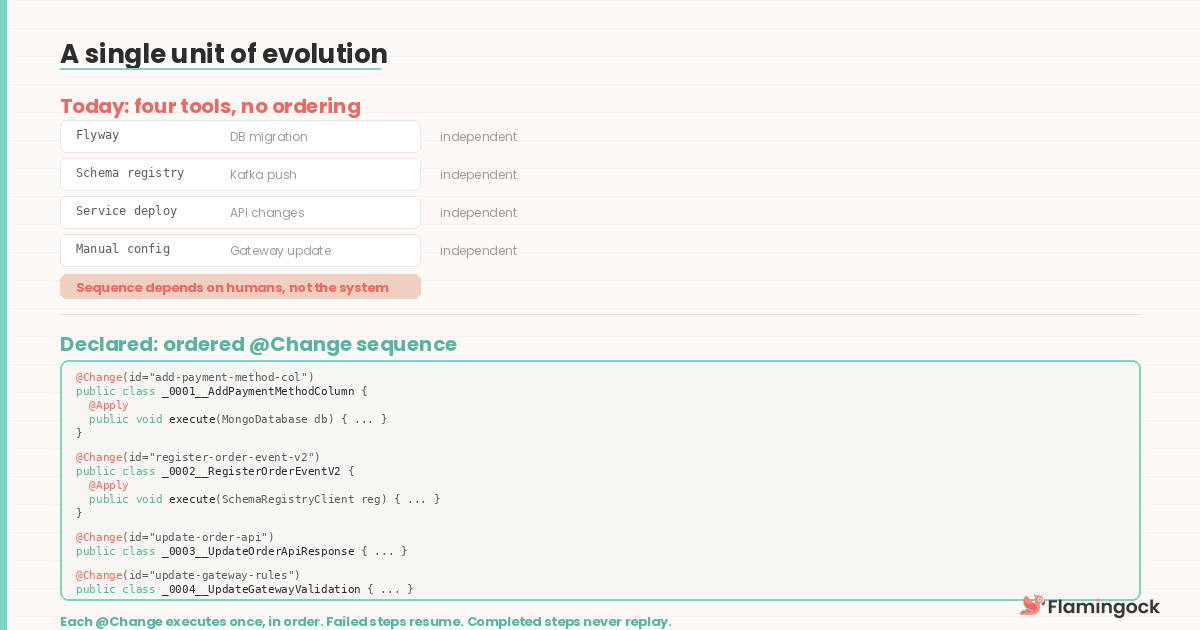
Consider a simple change in the order domain: adding a paymentMethod field.
This touches four systems: the database, the Kafka event schema, the REST API, and the API gateway. Each change is discrete, but the order matters. The database must change first. Consumers must tolerate the new event shape before it is emitted. The API must align with both.
Expressing change as code means declaring that sequence as a single, ordered set of change units:
@Change(id = "add-payment-method-column")
public class _0001__AddPaymentMethodColumn {
@Apply
public void execute(MongoDatabase db) {
db.getCollection("orders")
.updateMany(new Document(),
set("paymentMethod", "UNSET"));
}
}
@Change(id = "register-order-event-v2")
public class _0002__RegisterOrderEventV2 {
@Apply
public void execute(SchemaRegistryClient registry) {
registry.register("order-events-value",
orderSchemaV2WithPaymentMethod());
}
}
@Change(id = "update-order-api-response")
public class _0003__UpdateOrderApiResponse {
@Apply
public void execute(ApiContractService contracts) {
contracts.addField("order-response",
"paymentMethod", FieldType.STRING);
}
}
@Change(id = "update-gateway-validation")
public class _0004__UpdateGatewayValidation {
@Apply
public void execute(GatewayConfigClient gateway) {
gateway.allowField("order-request",
"paymentMethod");
}
}
The ordering is established by the class name prefix — _0001_ through _0004_ — so the sequence is visible in the file listing and enforced by the framework. Each change unit targets a specific external system — database, schema registry, API contract, gateway — and the framework executes them sequentially. The sequence is treated as a single unit of evolution.
Each change unit executes once and is recorded. If execution stops midway, it resumes from the point of failure rather than replaying completed changes. Steps that have already succeeded are never re-executed — the system is idempotent by design.
Execution at application startup

In most cases, this sequence runs during application startup — before the service begins accepting traffic.
The application evaluates which changes have already been applied and executes the remaining ones in order. This extends the model that tools like Flyway and Liquibase established for database migrations, but broadens the scope to every external system the application depends on.
In distributed environments, execution happens in lockstep. One instance applies the sequence while others wait. This prevents multiple nodes from attempting the same cross-system changes concurrently — a race condition that becomes inevitable at scale without coordination.
The result is consistent evolution across environments. Every instance, every region, every environment progresses through the same declared sequence, without manual coordination.
When startup isn't enough
Some changes don't fit the startup model. Large migrations — backfilling millions of rows, reprocessing historical events, restructuring a data store — can take hours. Blocking application startup for that duration isn't practical.
In these cases, the same sequence can be executed via a CLI. The model doesn't change — only the trigger does. The ordering guarantees, the lock coordination, and the audit trail all apply. The team declares the sequence once and chooses how to execute it based on the operational context. The application picks up the new state on its next deployment cycle.
What the team actually owns

Change-as-Code changes the ownership model for cross-system changes.
Today, a pull request for the new paymentMethod field contains service code — the updated domain model, the new API endpoint, tests. The evolution sequence lives somewhere else: a Confluence page describing the migration plan, a Slack thread coordinating the schema registry update, a runbook for the gateway change. The reviewer sees the code but not the rollout path.
When the change sequence lives alongside the code, the PR contains both the implementation and the evolution that carries it across every system boundary. A reviewer can see what's being modified, in what order, and what each step depends on. They can challenge the ordering. They can ask whether the gateway update should happen before or after the API change. Operational risk becomes visible during code review rather than surfacing during deployment.
And the audit trail — which changes were applied, when, in what order, and to which target systems — is inherent in how the change was executed, not reconstructed from deploy logs and interviews after the fact.
What comes next
Declaring change as a sequence gives application teams a way to describe and own system evolution. The runtime ensures that sequence is executed safely — with lockstep coordination across distributed instances, failure recovery, and a durable record of what was applied.
The next question is how those guarantees are implemented internally. The next post explores the architecture of the execution layer itself: how it coordinates across nodes, handles mid-sequence failure, and maintains the evolution ledger.