The last post introduced the execution layer — a runtime capability for governing how cross-boundary changes unfold as a system evolves. The incident made the case: when four coordinated changes hit three regions without governed sequencing, the result was identical configuration and divergent behavior.
This post asks the harder question: if such a layer exists, what must it guarantee — not aspirationally, but as architectural commitments that hold under real conditions?
The requirements fall into three categories:
What the layer must enforce

Deterministic ordering
In the Post 5 incident, the plan was IdP first, then app deployment, then gateway policies, then the feature flag. The plan was sequential. The execution was not — because nothing enforced the sequence at runtime.
If behavior depends on accumulated change, ordering cannot be incidental. When the order drifts, behavior drifts. An execution layer must make ordering explicit and enforceable, independent of propagation timing or human coordination.
Without deterministic ordering, evolution is opportunistic — and opportunistic systems produce non-deterministic outcomes at scale.
Convergence before progression
In distributed systems, "applied" is not "converged." In the Post 5 incident, the gateway policy was accepted in all regions, but EU-West had not finished propagating. If the execution layer had been verifying convergence rather than acceptance, step 3 would have remained active — blocking the feature flag until global propagation was confirmed.
An execution layer must verify that a change has stabilized across the boundary it affects before advancing. Not just that a request succeeded, but that the system has absorbed the change. Without this, sequence guarantees live in documentation while the runtime ignores them.
Lockstep where semantics require it
Not every change requires strict sequencing. Independent deployments, internal refactors, non-breaking configuration changes — these can proceed in parallel without coordination overhead.
But when cross-boundary behavior is affected — when an identity provider update must land before a gateway policy references new roles — timing becomes architectural. An execution layer must distinguish between changes that can proceed independently and those that require lockstep progression. The overhead of coordination should be selective: applied where order affects semantics and skipped where it doesn't.
Getting this boundary wrong in either direction is expensive. Too broad, and you've built a coordination bottleneck that slows every team — the execution layer becomes the thing platform engineers route around rather than rely on.
Too narrow, and you miss the sequencing failures you set out to prevent, which is where the Post 5 incident lived: the changes that needed lockstep didn't get it because the system had no way to express that some sequences are load-bearing and others aren't. The decision of what requires lockstep is itself an architectural choice, and the execution layer needs to support it explicitly rather than treating all changes as equal.
What the layer must remember

The evolution ledger
If the path shapes behavior, the path must be queryable. This is where the execution layer diverges most sharply from logging infrastructure.
Logs capture events. A ledger captures causality.
An execution layer requires a durable record: the declared sequence, the actual execution order, convergence checkpoints, cross-system acknowledgments, and any out-of-sequence mutations.
This record is not a debugging aid — it is the source of truth for how the system arrived at its current state.
In the Post 5 scenario, there was no trace of the sequencing failure after the fact because every system converged to the same snapshot. The ledger makes the path visible even when the destination looks correct. Without it, diagnosing divergence becomes forensic reconstruction across logging systems. At small scale, that's tedious. At platform scale, it fails.
Auditability as a property, not a process
The ledger makes audit structural rather than retrospective. The system should be able to answer what changed, in what order, who initiated it, and whether convergence was confirmed before the next step advanced — not by assembling logs from five systems after the fact, but by design, as an inherent property of how the evolution was executed.
In regulated or multi-team systems, this is not optional. It is the difference between provable sequencing and reconstructed belief.
Most audit processes today work backward from an outcome, correlating deploy records and interviewing teams about what happened when. An execution layer with a proper ledger works forward from intent — the declared sequence is the audit trail, and deviations from it are recorded as they occur rather than discovered weeks later.
What the layer must survive
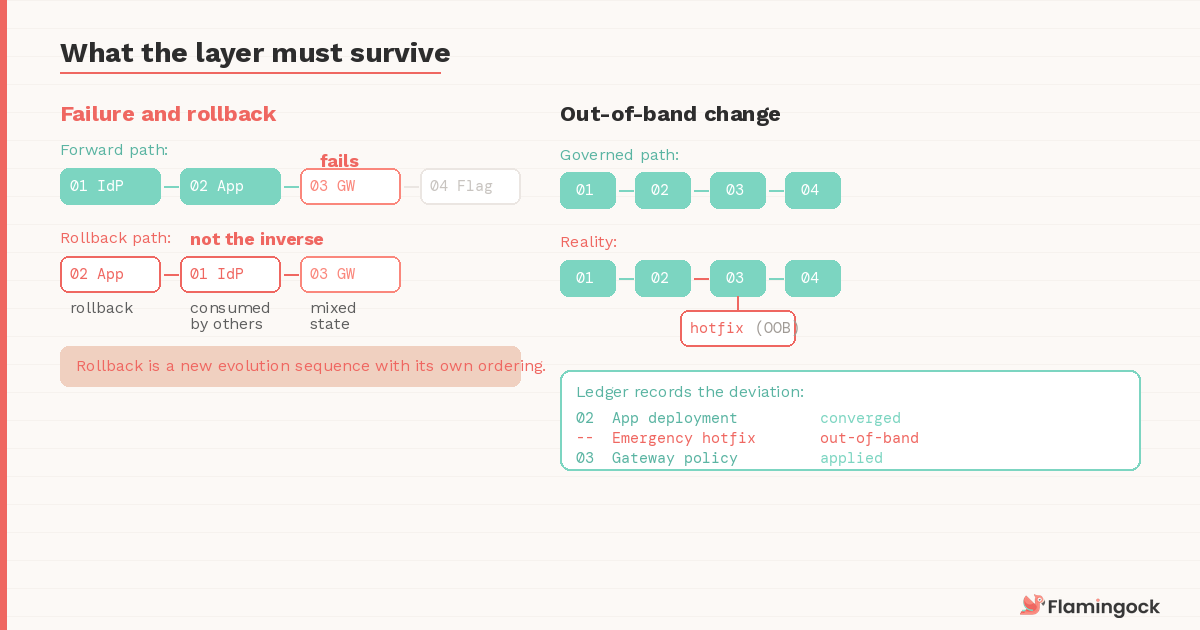
Failure and rollback
Governance is tested under failure, and distributed rollback is rarely symmetric.
Consider the Post 5 scenario with one change: the gateway propagation fails entirely in EU-West after the IdP roles and application have already updated. The IdP change may have been consumed by downstream systems. The application is already serving traffic against the new role definitions. Rolling back the IdP update doesn't undo the requests that already resolved against it, and reversing the application deployment while the gateway is in a mixed state could create a different inconsistency. The rollback path is not the inverse of the forward path — it's a new evolution sequence with its own ordering requirements.
An execution layer must define how failure halts progression, how partial convergence is handled, and when forward correction replaces reversal. Failure must be modeled as part of the evolution path, not treated as an operational exception. Without this, recovery becomes improvisation under pressure — with no structural record of what was attempted and no deterministic proof that the system returned to a consistent state.
Out-of-band change
Manual fixes happen. Vendors push updates. An emergency hotfix bypasses the governed path under production pressure.
An execution layer must detect and surface these out-of-sequence mutations rather than silently absorbing them. The ledger should reflect deviations explicitly so they can be reconciled — not as failures, but as recorded departures from the declared sequence. If the ledger diverges from what actually happened, every guarantee built on top of it — ordering, convergence, audit — degrades quietly until someone discovers the gap during an incident or an audit, which is precisely when you can least afford it.
What actually changes
Post 5 described the shift conceptually — you stop debugging distributed side effects and start governing causality. These requirements make that shift concrete.
Without deterministic ordering, you are coordinating by convention. Without convergence verification, your sequence is aspirational. Without the ledger, your audit is reconstruction. Without failure modeling, your recovery is improvisation.
These guarantees are interdependent. Remove one, and the others degrade — not catastrophically, but in the quiet, compounding way that distributed systems fail: slowly enough that nobody notices until the incident reveals how far things have drifted.
What comes next
Defining these requirements is straightforward. The real challenge is satisfying them simultaneously — without centralizing control into a coordination bottleneck that slows every team in the organization.
In the next post, we'll examine execution models that attempt to meet these guarantees, and where the line falls between deterministic governance and the rigidity that turns platform teams into gatekeepers rather than enablers.