The previous post described what an execution layer must guarantee: deterministic ordering, convergence verification, a durable evolution ledger, and the ability to survive failure and out-of-band change.
Defining those requirements was the straightforward part. The harder question is how to satisfy them without turning the execution layer into a central bottleneck — without recreating the kind of rigid control plane that modern architectures spent a decade dismantling.
That question is what separates execution models from each other.
Models that fall short

Human-orchestrated sequences
Most organisations already have a de facto execution model. A rollout plan lives in a document or a spreadsheet. Teams coordinate on a call or in Slack. Steps are executed manually or through separate pipelines. Dashboards are monitored. If something looks wrong, someone rolls back.
This works surprisingly well at small scale. The problem is not that teams are careless — it's that the system itself is unaware of the plan. The sequence exists in documentation, not in runtime. Ordering depends on coordination. Convergence depends on someone watching a dashboard. Audit depends on reconstructing what happened from logs and memory after the fact.
The Post 5 incident is a textbook example: every team executed their change correctly. The failure emerged from the absence of a runtime mechanism enforcing the intended sequence. Three teams, four changes, one spreadsheet with "confirm done" checkboxes — and a sequencing failure that took hours to diagnose because the system had no record that order mattered. The gateway policy and the feature flag needed lockstep progression — the flag couldn't safely activate until propagation had completed globally. But lockstep in this model is a verbal agreement on a call, and verbal agreements break the moment someone confirms prematurely or a timezone gap means the confirmation comes too late.
Human orchestration is not an execution model. It is a coordination pattern.
Pipeline-centric execution
The natural next step is to encode the sequence in a CI/CD pipeline. A single pipeline runs the four steps in order, removing manual coordination. This improves repeatability, and for changes within a single deployment boundary it works well.
But pipelines govern artifacts, not system state. They execute commands and observe immediate success or failure, but they rarely verify runtime convergence across external systems. In the Post 5 scenario, a pipeline could fire the gateway policy update and receive a 200 back — but that 200 means the request was accepted, not that EU-West has finished propagating. The pipeline moves to step four. The feature flag activates. The 403s begin. Some teams work around this by inserting sleep timers or hardcoded waits between steps — a five-minute pause after the gateway update before enabling the flag. But a sleep timer isn't lockstep. It's a guess about propagation speed dressed up as sequencing. When propagation takes six minutes instead of four, the guess fails silently.
This produces a familiar pattern for anyone who's operated a platform at scale: the pipeline succeeds, the rollout looks complete, and runtime divergence surfaces hours later when someone notices behavioural anomalies that no deployment record explains. Pipelines solve execution automation. They don't solve evolution governance — because they can't see beyond the boundaries they were built to operate within.
Central orchestration
Some organisations try a stronger approach: a centralised orchestration system that coordinates cross-system change. In theory, this provides explicit sequences, dependency management, and visibility into execution state — closer to the execution layer described in Post 6.
In practice, it introduces a different problem. When every cross-boundary change must route through a central orchestrator, the platform team becomes a gatekeeper for system evolution. Lockstep progression works mechanically — the orchestrator can enforce that step two waits for step one to converge. But consider what this looks like operationally: a payments team needs to update their API contract, which requires a coordinated change to the gateway and the downstream fraud detection service. The sequence needs lockstep between the contract update and the gateway propagation. Instead of declaring that lockstep and executing it themselves, they file a ticket with the platform team and wait for the orchestrator to schedule it. The two-day change takes two weeks — not because lockstep is hard, but because every lockstep dependency in the organisation flows through the same queue.
The architecture gains determinism but loses the autonomy that made microservices worth adopting in the first place. And the orchestrator itself becomes a critical control plane — if it goes down or its queue backs up, evolution stalls across the organisation. Modern distributed systems were explicitly designed to avoid this kind of centralised coordination dependency.
The constraint that matters
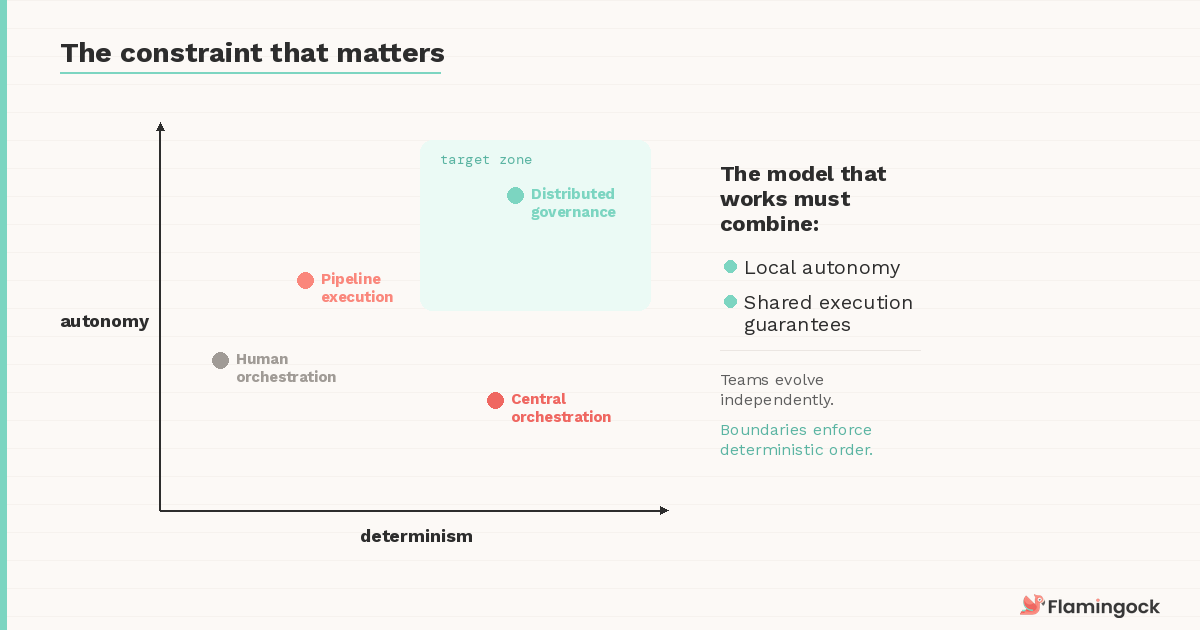
Every model above fails on the same tension. The execution layer must satisfy two requirements simultaneously: deterministic evolution across boundaries, and autonomy within those boundaries.
Teams must remain free to evolve their systems independently. But when changes cross boundaries — when an identity provider update must land before a gateway policy references it — the ordering guarantees must become enforceable. Not by routing everything through a central team. Not by hoping everyone follows the runbook. By design.
This rules out purely centralised orchestration (which sacrifices autonomy) and purely decentralised coordination (which sacrifices determinism). The model that works must combine local autonomy with shared execution guarantees — allowing teams to evolve independently while preserving deterministic order where boundaries intersect.
Distributed execution governance
The approach that resolves this tension treats the execution layer as a distributed governance capability rather than a centralised controller. The distinction matters architecturally.
In a centralised model, the orchestrator owns the execution. It decides what runs, when, and in what order. Teams submit their changes and wait. In a distributed governance model, teams own their execution. They declare evolution sequences as part of their change definition — the same way they declare infrastructure as code or feature flags as configuration. The execution layer doesn't perform the actions. It governs the ordering and observability of those actions across system boundaries.
This resolves the bottleneck problem because no central team sits between a change and its execution. The payments team declares their API contract update as a three-step sequence: update the contract, propagate the gateway change, notify the fraud service. The lockstep between the contract update and gateway propagation is part of the declaration itself — not a ticket filed with another team, not a verbal agreement on a call, not a sleep timer in a pipeline. They own the declaration. They trigger the execution. But the execution layer enforces that step two doesn't advance until step one's convergence has been verified across the affected boundary, and the evolution ledger records the actual path — including any deviations from the declared sequence.
The structural difference from pipelines and orchestrators is worth naming explicitly.
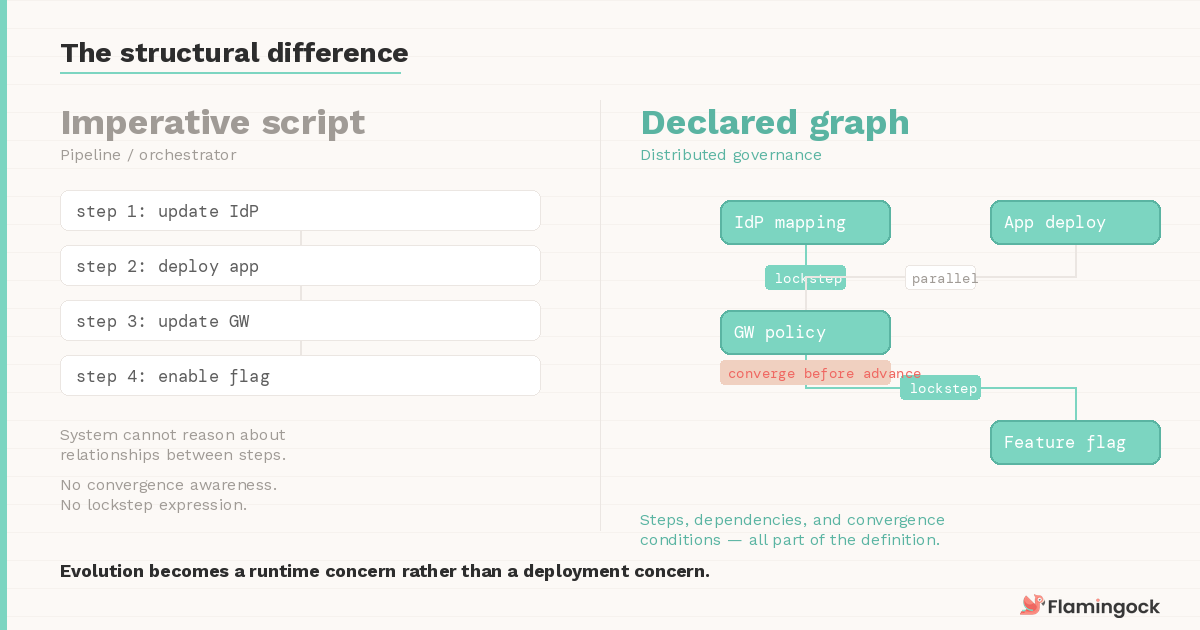
In those models, the change is an imperative script — a sequence of commands whose relationships the system cannot reason about. In a distributed governance model, the change is a declared graph: the steps, their dependencies, and their convergence conditions are all part of the definition. The execution layer doesn't run the graph top to bottom. It evaluates which steps can advance based on the current state of the system. This is what allows independent changes to proceed in parallel while load-bearing sequences enforce lockstep — the graph expresses both, and the runtime resolves them differently.
In other words, evolution becomes a runtime concern rather than a deployment concern.
Convergence checkpoints replace the pipeline's assumption that "accepted means done." The shared ledger replaces the post-mortem's reliance on log correlation. Out-of-band changes — the emergency hotfix that bypasses the sequence — are surfaced as recorded deviations rather than absorbed silently. The system retains autonomy at the team level while the execution guarantees hold at the platform level.
The layer governs causality, not implementation.
Why this is still rare
If the need is clear, why do so few systems work this way today?
The industry spent the last decade solving delivery automation — CI/CD, infrastructure-as-code, container orchestration. Those tools dramatically improved deployment speed and reliability. But they largely treated system evolution as a side effect of artifact delivery. Ship the code, provision the infrastructure, toggle the flag — and assume the cross-boundary consequences will sort themselves out.
As systems became more distributed — with external identity providers, policy engines, service meshes, and SaaS dependencies — that assumption started breaking down. Evolution crossed boundaries that delivery pipelines were never designed to govern. The tools matured. The architecture matured. But the coordination model between them didn't.
That's the gap this series has been exploring. The execution layer is the architectural response to it.
What comes next
This post described where the execution layer fits on the spectrum of coordination models. The next question is more concrete: where does it live in the architecture?
Treating the execution layer as a runtime capability — something embedded in how evolution is declared and executed, rather than bolted on as a pipeline stage or an orchestration service — changes how teams interact with it and how governance scales across the organisation.
In the next post, we'll look at what that runtime capability looks like in practice, and how it changes the relationship between platform teams and the services they support.