The previous post showed what the interface looks like: ordered @Change classes, each targeting an external system, executed at application startup in sequence. The team owns the definition. The framework owns the guarantees.
This post opens the engine. What actually happens between the moment the application starts and the moment it begins serving traffic?
The startup sequence

When an application starts, the execution layer activates before the service accepts any requests. This placement is deliberate: no request reaches a system where the database has a new column but the API doesn't expose it yet, or where the event schema has been updated but consumers haven't been aligned. The system doesn't serve partially applied change.
The process follows a specific sequence.
Lock acquisition. The engine acquires a distributed lock to guarantee that only one instance executes changes at a time. In a deployment with multiple replicas, the others wait. Once the lock holder finishes, waiting instances verify that all changes have been applied and proceed to serve traffic.
Once the lock is held, discovery follows. The engine scans the classpath for @Change classes and reads the class name prefixes to assemble the ordered sequence. In the paymentMethod example from Post 9, this means discovering _0001__AddPaymentMethodColumn, _0002__RegisterOrderEventV2, _0003__UpdateOrderApiResponse, and _0004__UpdateGatewayValidation — the full picture of what the application declares as its evolution path.
State comparison. The engine then queries its change log — a persistent record of which changes have already been applied. Each entry records the change id, when it executed, whether it succeeded, and the instance that ran it. The engine compares the declared sequence against the log and identifies which changes are pending.
This is where idempotency is enforced. A change that has already succeeded is never re-executed, regardless of how many times the application restarts. If the application crashed after _0002__RegisterOrderEventV2 completed but before _0003__UpdateOrderApiResponse began, the next startup skips the first two changes and resumes from step three.
Sequential execution. Pending changes execute one at a time, in order. For the paymentMethod sequence, this means the engine adds the column first, then registers the new event schema, then updates the API contract — never exposing a field before it exists in the database, never emitting events in a format consumers haven't been prepared for.
After each change completes, the engine writes a success record to the change log before advancing. This write-then-advance pattern is what makes failure recovery deterministic: if the application crashes between executing a change and recording it, the engine re-executes that specific change on the next startup — but only that one, because the previous changes are already recorded.
Once all pending changes are applied and recorded, the engine releases the distributed lock. The application proceeds to initialise its HTTP listeners, message consumers, and health check endpoints. Other instances that were waiting on the lock verify the change log, confirm everything is applied, and start serving traffic themselves.
What happens when something fails

Failure during change execution is not an edge case — it's an expected operating condition. Networks drop. External services return errors. Schema registries reject malformed schemas. The engine handles failure as a normal part of the execution path, not as an exception that requires human intervention.
Consider the paymentMethod sequence. The database column is added successfully (_0001__). The Kafka schema registration succeeds (_0002__). Then the API contract update fails — the contract service is temporarily unavailable (_0003__).
The change log now contains two success records. The third change has no record. The application cannot proceed, so it reports the failure and stops startup. It does not silently start serving traffic with a partially evolved system.
On the next restart — whether triggered by a deployment retry, an orchestrator health check, or a manual intervention — the engine acquires the lock, scans the change log, and finds that _0001__ and _0002__ are recorded as successful. It skips them and attempts _0003__ again. If the contract service is now available, execution continues through _0003__ and _0004__. If not, it fails again and the cycle repeats.
This is the default behaviour — manual intervention — and it's the right default for changes that modify critical system state. But the recovery model is more sophisticated than "halt and wait."
Flamingock supports configurable recovery strategies per change. A change annotated with @Recovery(strategy = ALWAYS_RETRY) will automatically retry on the next execution cycle rather than blocking — appropriate for idempotent operations where failures are typically transient. The team chooses the recovery posture that matches the risk profile of each change, not a one-size-fits-all policy. When failure does require investigation, the CLI provides a structured resolution workflow — surfacing diagnostic context, guiding target system verification, and recording the resolution.
This matters because failure in cross-system change sequences is fundamentally different from failure in single-database migrations. A change that modifies a schema registry and then fails on the API contract update leaves one system changed and another unchanged. The right resolution depends on what actually happened in the target systems, not what the engine thinks happened.
The team's job during a failure is to fix the root cause, verify the target system state, and mark the resolution. The engine's job is to ensure the sequence remains intact regardless of how many restarts occur between failure and resolution.
The change log as evolution ledger
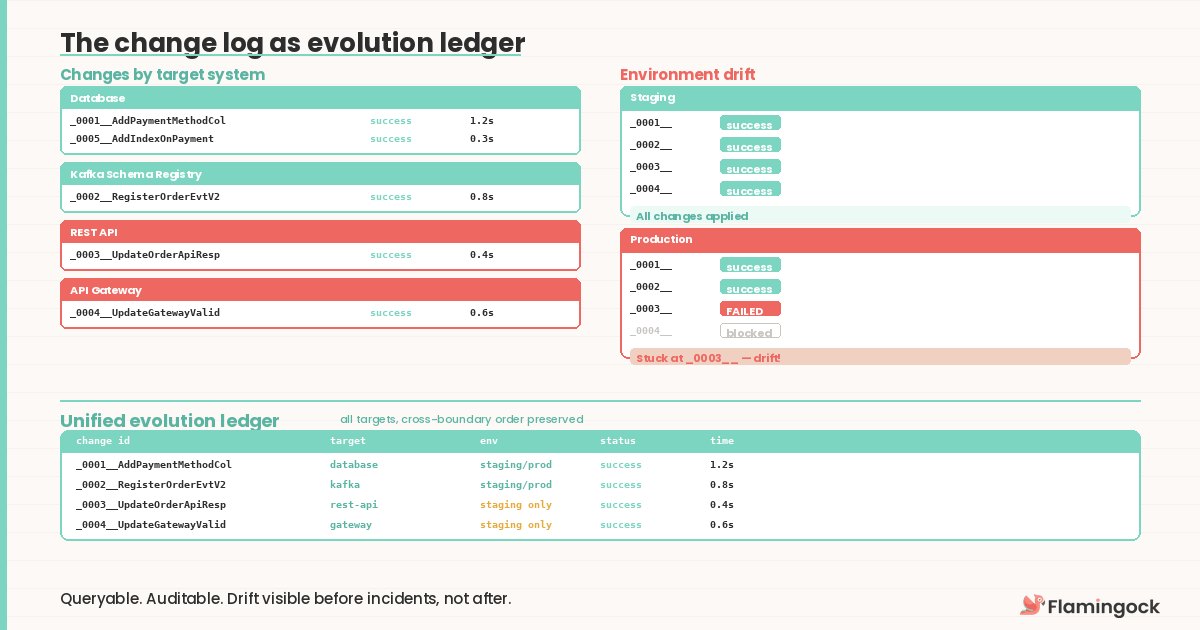
The change log is more than a state comparison table. It's the evolution ledger the series has been describing since Post 6 — and what makes it different from a typical migration table is that it spans systems. A Flyway log tells you which SQL scripts have been applied to one database. The evolution ledger tells you how the application's full external footprint arrived at its current shape: what changed, when, which instance ran it, the outcome, and the duration.
This record is queryable. When compliance asks "in what order were these changes applied across systems?" the answer is a structured report, not a week of log correlation. Environment drift becomes visible too — if staging has applied changes through _0004__ but production is stuck at _0002__, the discrepancy is immediately apparent rather than discovered during an incident.
Because the ledger captures changes across different target systems, it becomes a governance surface. A platform team can see which services have applied their latest changes, which are blocked, and which target systems are affected — with cross-boundary ordering preserved.
The change log is deliberately separate from the target systems it records changes against. The audit record for a database migration shouldn't live inside the database being migrated. This separation means the same architecture supports a local audit store today and a centralised, cross-service view tomorrow — where changes from dozens of services are queryable and visualisable in one place.
The CLI: operations beyond startup
The CLI isn't a different tool — it's the same engine with a different entry point. For executing changes, it invokes the identical sequence: acquire lock, discover, compare, execute, record, release. The @Change classes, the change log, and the guarantees are identical. The difference is operational context — startup execution blocks the application until changes complete, while CLI execution runs independently.
But the CLI isn't only for running changes. It's the operations interface for the entire evolution lifecycle. An ops engineer can query the audit trail, inspect failures, and resolve issues without the application being running or restarted. The team that writes the @Change classes owns the definition. The ops team that manages production has the tools to inspect, diagnose, and resolve without touching application code or waiting for a deploy cycle.
This is what Flamingock builds
The architecture described in this series is not a theoretical framework. Flamingock is a Change-as-Code platform — JVM-native today, with a polyglot roadmap — that implements it as an application-owned capability managing the full lifecycle of system evolution: declaration, execution, recovery, and governance.
The platform delivers the guarantees enterprise systems require: deterministic cross-system ordering, distributed locking without external coordination infrastructure, configurable recovery strategies matched to each change's risk profile, and a durable evolution ledger — separated from target systems by design — that provides queryable, auditable proof of what changed, when, and across which systems. Security is structural: changes execute inside the application's own runtime with no external agents, no sidecar processes, and no credentials shared with third-party services. The audit trail is inherent in how changes execute, not reconstructed after the fact.
It started as Mongock — a MongoDB migration tool used in thousands of production applications — and evolved into a platform that governs change across every external system an application depends on.
The series ends here. Ten posts, one architecture, one platform. The model is concrete, the engine is open, and the code is running. If this matches the problems you're solving, the next step isn't another post — it's running it.