The previous post showed why pipelines, orchestrators, and human coordination all fail on the same constraint: they sit outside the runtime where the system's actual state emerges. A pipeline can submit a change and receive confirmation that it was accepted. What it cannot observe is the moment the system reaches the state that change depends on.
That gap determines where the execution layer must live in the architecture.
The runtime, not the delivery path
Consider a service mesh policy update. A platform team modifies a routing rule to gradually shift traffic from one service version to another. The change propagates through control planes, sidecars, and regional clusters. During that propagation window, dependent systems must behave differently — feature flags might need to remain disabled until traffic distribution stabilises, observability rules may need temporary adjustments while both versions are active.
From the pipeline's perspective, the change finished when the policy was accepted. From the system's perspective, it may still be unfolding.
This is the same dynamic as the Post 5 incident — a gateway that returned 200 while EU-West was still propagating. The boundary is different. The pattern is identical: the delivery tool reports success before the system has converged.
A useful analogy comes from database transactions. Transaction managers don't sit in build pipelines or deployment scripts. They exist inside the database engine because only the engine can determine when writes are committed, rolled back, or conflicting with other operations. Attempting to coordinate transactions externally would quickly become unreliable.
System evolution has the same property. The ordering guarantees only matter if they're evaluated against the state the system is actually reaching — not the commands that were issued. This is why the execution layer functions as a runtime subsystem rather than a deployment tool.
What the runtime layer actually observes

To see why placement matters in practice, consider a payment platform integrating a new external identity provider. The migration requires four steps, each touching a different boundary:
- Introduce support for the new provider in the authentication service
- Update gateway policies to recognise the new tokens
- Gradually route authentication traffic through the new provider
- Retire the legacy provider once token validation stabilises
A pipeline can launch those changes. What it cannot determine is whether the platform has reached the state that allows the next step to proceed safely. Is token validation stable across regions? Has the gateway fully propagated the new policy? Is the traffic shift producing the expected error rates?
The runtime execution layer evaluates that progression continuously. It observes the declared sequence, monitors the signals that indicate convergence at each boundary, and advances the evolution only when those signals confirm readiness. Some steps advance immediately. Others wait. Independent changes proceed in parallel while load-bearing sequences are held in lockstep — the same selective enforcement Post 6 described as a structural requirement, now evaluated against live system state rather than declared intent alone.
Because the evaluation happens at runtime, the guarantees reflect the system's behaviour rather than the assumptions embedded in the deployment script.
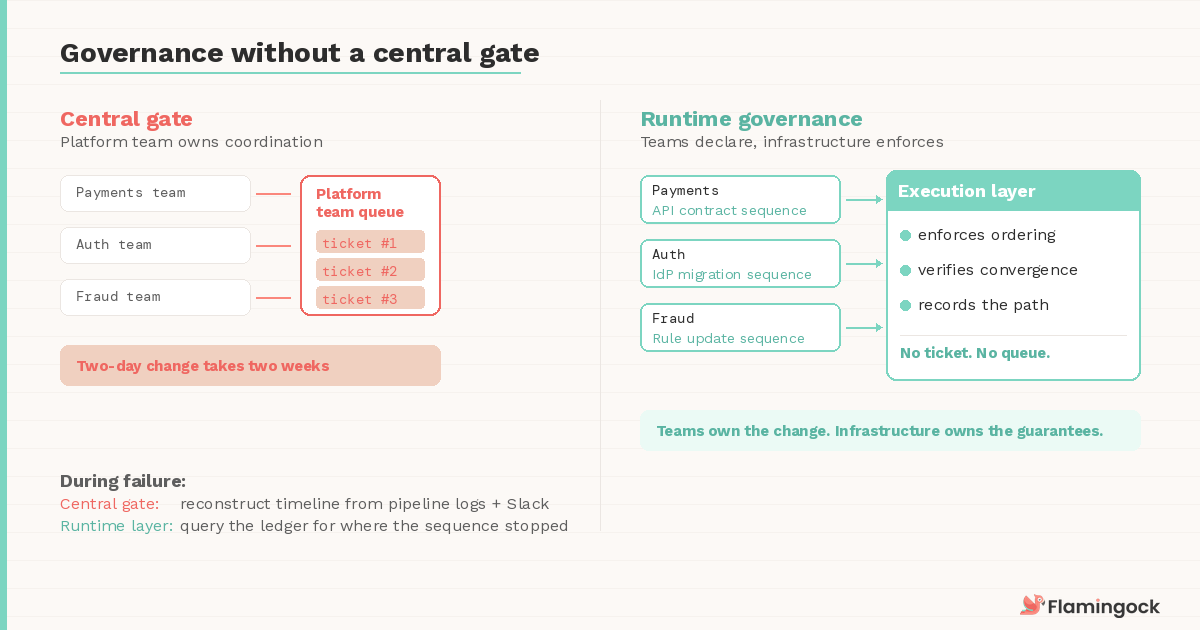
Governance without a central gate
Runtime placement also changes how governance works in practice.
In many organisations, platform teams become responsible for coordinating complex changes simply because they operate the systems where those changes intersect. Over time this produces an informal queue — service teams planning upgrades, schema changes, identity migrations, or traffic shifts ask the platform group to schedule the coordination. The queue grows not because the platform team lacks tooling, but because the system lacks a way for teams to declare those dependencies themselves.
When the execution layer lives in the runtime, teams declare the sequence as part of their change definition — the declared graph from Post 7. The platform infrastructure enforces the ordering guarantees, but it doesn't own the change. Governance emerges from shared execution rules rather than centralised scheduling.
This distinction becomes most visible during failure recovery. If a rollout pauses because a dependency hasn't converged, the system records that state directly. Teams can see where the sequence stopped, what signals are missing, and when execution can safely resume. The investigation focuses on the state transition rather than reconstructing a timeline from pipeline logs, deploy records, and Slack messages — the forensic reconstruction problem Post 6 identified as the alternative to a proper evolution ledger.
Evolution across boundaries you don't control
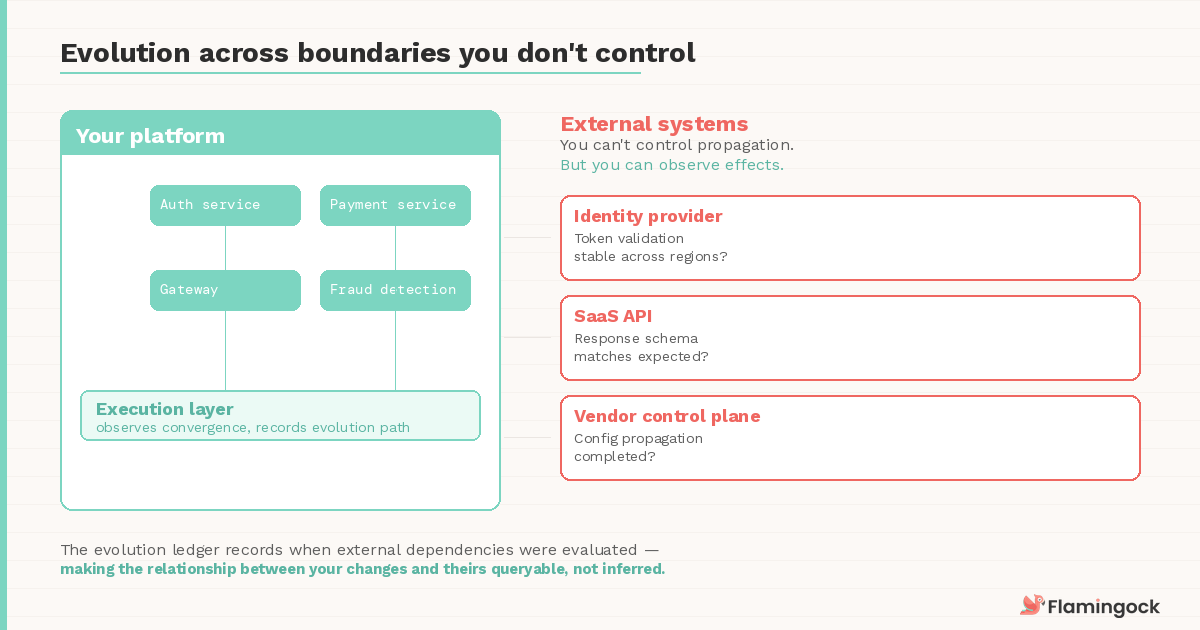
The strongest case for runtime placement comes from systems that interact with platforms evolving independently.
SaaS services, external identity providers, and third-party APIs introduce their own propagation delays and version transitions. Your deployment pipeline has no visibility into when a vendor's control plane has finished propagating a configuration change. Your orchestrator can't poll an external identity provider for convergence state.
But the runtime environment can observe the effects. It can monitor whether token validation against the new provider is returning the expected results across regions. It can detect that a third-party API's response schema has shifted in a way that affects downstream processing. It can distinguish between a fault in your platform and drift in an external dependency — a distinction that's surprisingly difficult to make when the only records are isolated deploy logs and monitoring dashboards.
This is where the execution ledger becomes most valuable. When the evolution path itself is recorded — including the points where external dependencies were evaluated — the relationship between your changes and the external system's behaviour becomes queryable rather than inferred.
Without that record, the post-mortem defaults to the same question every time: "did something change on their side, or ours?"
What comes next
If the execution layer lives in the runtime, another question follows naturally: how do teams interact with it?
Declaring evolution sequences, monitoring convergence signals, and recording the path of change all require a representation that both humans and systems can understand. System evolution needs a form of expression that is structured, reviewable, and executable.
The next post explores that representation — how evolution itself can be defined as code, and how that definition becomes the interface between teams and the execution layer that governs it.